
Manipulating Energy, Matter, and Compute: A Tale of Cellular Biology and Robotics
How the thermodynamics of organic life and industrial civilizations exist at extreme ends of a scale spectrum and biology may provide our best robots.


The limit of what is knowable is bounded by whats observable. Telescopes pushed back the veil of ignorance on the night sky and revealed planets are in fact other worlds with their own moons, and we were made to feel incredibly small. Microscopes revealed a hidden world embedded in the fine structure of all living systems, that plants and animals are themselves made of smaller creatures, and we were made to feel incredibly big. We are trapped in the middle of a scale spectrum whose bounds are set by the limits of measurement, and for now it looks like we’ve reached ‘the ends’ of reality: telescopes can see into the past to when empty space cooled enough to be transparent by letting hot proton-electron plasma to condense into hydrogen, and particle accelerators are powerful enough to see the building blocks of what those protons are made of.
Living systems occupy a distinct region of the scale spectrum that has a definite lower-bound - what is the minimal self-replicating molecular assembly, which is around 500 genes with a molecular weight of 500 megadaltons. This is similar to asking ‘what is the minimum complexity of a self-sustaining technical civilization’ and finding an answer of around a million people. Both living organisms and societies achieve specialization of function by scaling up, and below a certain scale there aren’t enough unique functions to acquire the energy and material resources to reproduce, nor process enough information to adapt to a changing environment. You need information processing power, or compute, and energy-matter manipulation power, or metabolism.
These days we stand ready to drastically expand our civilizational capacity for processing information via artificial intelligence, and similarly expand our industrial metabolism through robotics and new sources of energy. This will unleash a scale of material, information, and energy abundance that is at least a comparable orders-of-magnitude jump as was the transition from animal and human labor in feudalism to machine power in the industrial revolution. We dream of giving birth to a new species altogether that is made of silicon and steel, intelligent and aware robots, that can withstand far harsher environments and do the heavy-lifting of colonizing new worlds or operating factories here on Earth.
This is the question of Mars, or any colonization program: “What is the minimum viable complexity of a silicon-and-steel industrial civilization to be self-sustaining and adapting in a harsh environment?”
It appears to be quite large and difficult to operate and maintain, nothing short of a global civilization to extract and mine all the raw resources, design the chips, operate the power plants, and so on. The ‘end-game’ level of technology for a silicon-and-steel civilizational stack is an industrial society that can unpack from a single unit from scratch when plopped into a new environment, the von Neumann probe. Is the minimum viable von Neumann probe the size of a house? A city? One might think with sufficiently advanced technology the ideal von Neumann probe can be the size of a grain of sand and consist of molecular nanobots that re-arrange material at the atomic scale, from there replicating and differentiating to scale up into something civilization-sized.
The irony in dreaming of von Neumann nanobots as the ultimate pinnacle of steel-and-silicon civilization is that when you peer at biological systems through a microscope, that’s exactly what you see - self-assembling, replicating, molecular machines and factories that unpack from a single cell into the most complicated objects in the known universe - the conscious and intelligent mind of a human, with all the circulatory and muscular systems required to sustain it. More than that, the living ecology of the whole planet came from single-celled ancestors given enough time. This is not just an analogy. DNA-RNA systems are fully Turing-complete computers able to execute genetic instructions as code, and the proteins produced through mRNA transcription are indeed molecular robotic systems that enable cells to acquire raw material resources and energy necessary to reproduce.
We are made of nanobots, molecular computing machines that adapt, evolve, and replicate, a tech-stack that can unpack a human being from a grain of sand.
We’ve just barely begun to understand and decode this technology in a way that we can make direct use of, and the highest value initial application is in understanding our own bodies and making us healthier.
The long-term application of biotech isn’t just human therapeutics or batch reacting agave for niche tequila brands, its growing things like structures, cars, factories, rocket ships, sprawling industrial complexes that unfold by molecular robots scooping up all the raw ingredients from their environments and assembling them into place on the fly. Biotech is the precursor to nanotech, and this article is going to explain how to get there.
Biology as a Tech Stack
The earliest man-made tools were simple modifications of things we found in nature - chipped flint arrowheads, carved bones, and so on. For biotech we are very much still at the stage of “picking up seashells off the beach and using them for other things” - CRISPR was first found as the self-defense mechanism in bacteria, and we’ve learned to take that and re-purpose it for gene editing, but this is a massive watershed moment that lets us directly edit the software of the biology stack. This is like the transistor moment for biology. Remember, transistors were first developed to replace vacuum tubes as compact reliable and extremely high-gain current amplifiers so we could do things like make hand-held radios. A few decades later and TSMC is developing 3nm technology, transistors just tens of atoms across, stacking them by the tens of trillions into single chips, stacking chips into Gigawatt-class data centers, and using this to embed and spew forth the sum total of human knowledge in sychophant chatbot assistants.
Similar to how we once dreamed of transistors to make smaller radios, today we are still mostly conceptualizing of biotech as “making new therapeutics to improve health” - that is just the barest beginning of what’s to come. There’s two big problems however.
The first is that humans are smart in terms of insight but dumb in terms of total bandwidth, and biology has both colossal depth but equally colossal breadth, such that biology is a field of a large number of incredibly narrow specializations. Biological systems haven’t been designed by any human mind and so its under no obligation to be comprehensible to any human mind - it can be as big and messy as it likes. It gets messy because it evolves blindly, endlessly, navigating the space of possible morphologies through a massively parallelized evolutionary search algorithm. The end-result is that biological systems are both incredibly elegant and efficient, with a single specific hormone serving dozens of different signaling functions simultaneously, and at the same time byzantine spaghetti kluge-code of complicated interdependencies. Somehow, in all that complexity, elegance, and chaos, they emerge to be fantastically robust and adaptable, like a thousand interlocked Rube-Goldberg machines falling together by accident into something that can survive anything from asteroid impacts to the harsh vacuum of space. Not just survive, but thrive.
There’s another issue with understanding biology, and its that humans aren’t robots. When we pipette tiny amounts of fluids our hands shake, we sneeze, the temperature of the room varies by the hour of day and across the year. In short, biological experiments are notoriously difficult to replicate consistently and doing so for the purpose of therapeutics production is arguably the hardest part - how to take some known molecule and scale up production reliably and produce an effective delivery mechanism. This is why pharmaceutical giants are what they are. Discovery is one thing, delivery is another (portfolio plug for Ligandal).
Here we stand on several hundred years of technological progress like champions of a dirt hill looking up at the Mt. Everest of billions of years of technological progress as embodied in our biological ecosystem and surrounding landscape of living things. What’s a techno-optimist to do? How do we become bio-Prometheans and steal this fire of the gods? Good news - AI can take on the breadth, and robots can do the dirty work.
Let me explain how we can get from the transistor of biology to the PC, and then the data center, and how this will unlock a tech stack billions of years in the making.

Microfluidics will be the PC for Biology and Robots the Datacenter
The history of computing is pretty interesting - computers at one point were more like cathedrals - massive, bespoke, sprawling, corporate edifices that singularly served the needs of hundreds of software parishioners. You would design a program on pen-and-paper and then upload it to a central computer, hoping it worked. Personal computing changed this completely. A computer you had all to your own, to trial and error software as much as you liked until it worked. Experimentation and prototyping flourished, and just about anyone could learn to develop new software.
But a PC isn’t enough to host a modern cloud service, you need a data center and all the infrastructure associated with connecting server racks to the internet. In the early days of the dot-com boom there was no ‘common infrastructure’ for the internet, everyone from Pets.com to Amazon had to build their own server infrastructure from scratch, requiring huge capital investments.
Now we have data centers and cloud infrastructure like AWS and Google Cloud that have entirely abstracted away the significant undertaking of taking software systems you first developed on a local PC and now want to deploy to tens of millions of users all over the world. Voila, at-home design, at-scale deployment.
Microfluidics and robots will do this for biology, and it’ll proceed in two stages:

The PC of Experimental Biology
First, the at-home biology wet lab version of a PC: a microfluidic system that can execute biological experiments in an extremely consistent and controlled manner by performing the logic-gate equivalent of biology experiments, moving and mixing tiny quantities of fluid. Rather than the punch-card of pipetting microliter fluids between 96-well plates by hand, microfluidic systems transport liquids between reaction chambers along channels often shaped so as to admit cells to pass through in single-file fashion, squeezed by mechanical actuators or osmotic pressure. It’ll start out like the early PC’s did - they shipped as barebones processor units with limited memory, and you could add-on things like graphics cards, sound cards, more memory, more RAM, etc, to beef up its capabilities. The add-ons for the PC of biology would be things like nano-pore sequencers, compact multi-channel confocal imaging microscopes for things like in-situ 3D spatial transcriptomics, and the like. Connecting the core functionality of liquid handling gate operations to data acquisition add-on modules are the PCI and USB of fluidic connectors and pneumatic interfaces. The PC of biology has a key difference from its software counterpart - the need to constantly swap out single-use fluidics cartridges to prevent experimental cross-contamination between runs and refill the consumable reagents. The marginal cost per-use of a biological PC is therefore much greater, but it would still be orders of magnitude faster and simpler than doing the wetlab work manually similar to the speed up between punch-card computing and having a glowing green terminal screen and keyboard.
That is the key goal here, and something that is inevitable for the future of biology - wetlab as an API, where you can compose a program as a sequence of instructions to execute and they’re performed reliably and consistently without tedious manual intervention. The variation of wetlab-work-by-hand that beleaguers experimental reproducibility has its direct equivalent for software in the earliest days of NASA when ‘computer’ was a job title and people did calculations with slide rules.
Wet lab work as an API call in a device that can feasibly sit on a desk is just the beginning, the necessary first step in letting a person design an initial experiment and test it out in small ways before deploying it at-scale. Experimental biology at-scale isn’t the same as software, where the same core feature set is scaled to serve a great deal many more users - that’s already been solved for by the pharmaceutical behemoths we have today and their engineering competence in producing sophisticated biologics in large quantity and high purity. The subtle difference is in recognizing that experimental biology is about first designing a protocol thats adequate to address a candidate search space of interaction mechanisms, and then actually searching through that space by iterating through large numbers of permutations of key experimental configurations. It’s not millions of users all interacting with the same set of features, but rather millions of variations of features tested against the same “user” (or organism, organoid, cell type, etc).
Addressing the scale-up of an experimental design that involves a huge number of permutations is an important thing to understand to appreciate why fully robotic laboratories will become the data centers of biology, and so it’s useful to illustrate with a more detailed example.
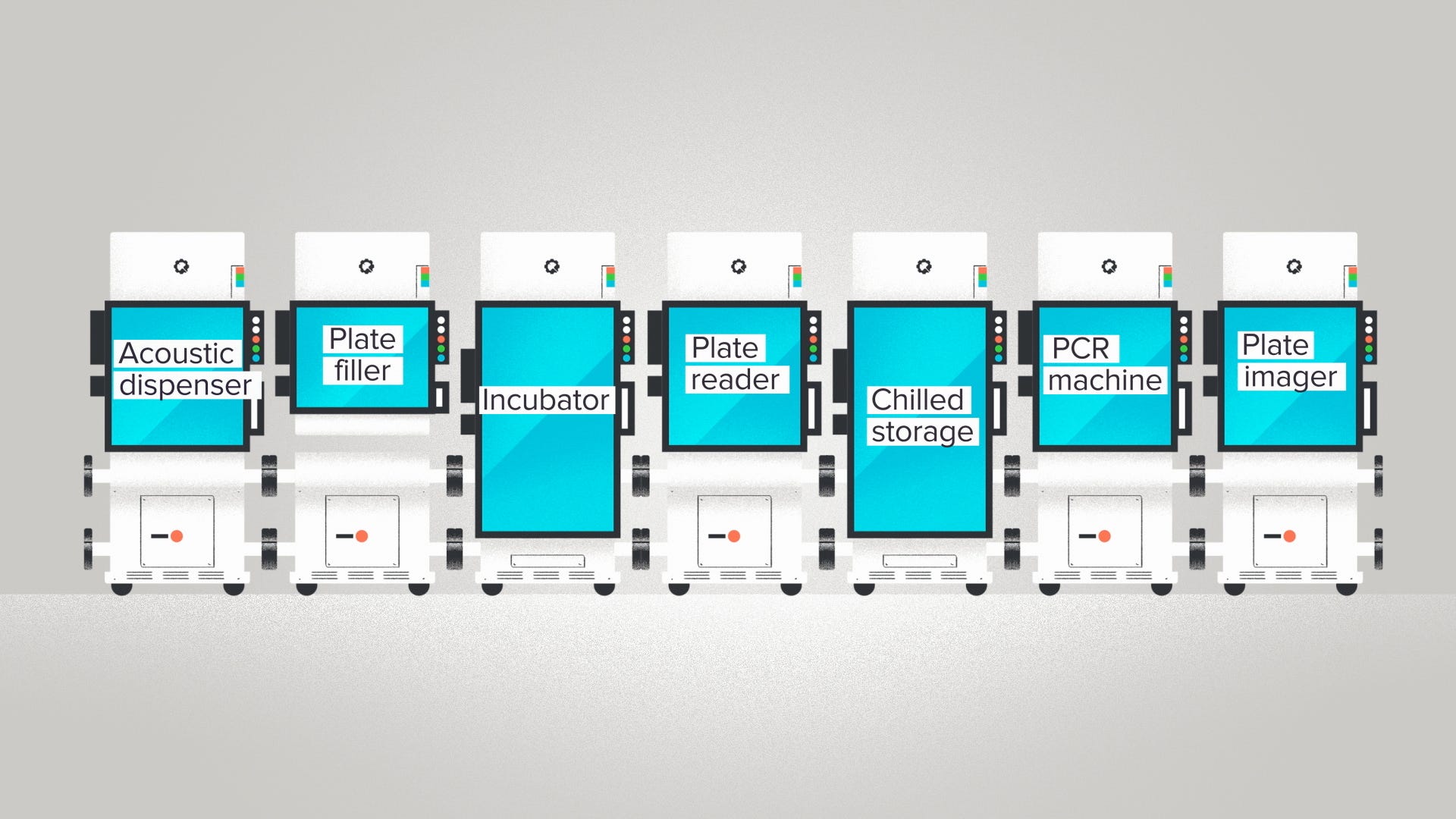
Robots are the Data Center (or more accurately, the Data Factory)
Lets consider a CRISPR knockout screen, which is like picking up a seashell off the beach and using it to carve into some poor animal to find out which parts of the animal are most essential for some function, like walking, or flying (it’s crude, bear with me) - more accurately you’re interested in finding genes that affect a particular phenotype, like drug resistance, or understanding which genes are responsible for a viral infection pathway. The experimental permutation you iterate over is testing which gene might be responsible for the effect you’re interested in. To do this you develop a library of guide RNAs that each target a different gene using the ‘found-on-the-beach’ seashell of CRISPR technology, get a large number of cells all from the same tissue type, e.g. epithelial lung cells if you’re interested in knowing which gene is responsible for COVID infections (we already know its ACE2, but whatever), and expose individual cells to each type of guide RNA. It’s the same experimental protocol each time as described by a directed graph, but you’re swapping out the content of the nodes.
If you wanted to canvass all the genes in the human genome you’d have to do this same thing 20,000 times, and for statistical robustness you should have something like 3 - 10 replicates of each knockout, meaning 10 copies of the same guide RNA + cell pairing.
After this you culture the cells for a couple weeks to and look to see what happens when you expose them to the conditions you’re interested in, like viruses - do some modified cells survive, or perish? This is the ‘easy’ version where you remove entire genes one at a time and see what happens, oh and have I mentioned tissue culture is a total bitch that is extremely error prone? No? Well it is. More than that, interesting biological properties are often a lot more complicated - there can be interactions across multiple genes, and it might not just be revealed by knocking the gene out entirely, but rather single-nucleotide point mutations somewhere along the gene giving different variants of a single gene.
Suppose you’ve narrowed down from the entire genome to 100 genes of interest, and want to explore pair-wise interactions. The number of pair-wise possible knockouts for 100 genes is 4,950 (100 choose 2). But that’s just knocking them out - genes often have multiple variants, sometimes caused by a change of a single base pair or single-nucleotide polymorphism (SNP). If there’s 4 versions of each gene, your pairwise analysis across 100 genes goes from 4,950 to 79,200 (100 choose two times 4^2). If there’s three genes that might be involved with four variants each? 100 choose 3 times 4 cubed, which is 10,348,800.
The great news is this is actually still massively simplified, since most complex traits and diseases are influenced by a lot more than just a few genes. Height? 700 genes. Type 2 diabetes or autism? 100 genes. The number of possible combinations of experiments to run rapidly explodes into the many-tens-of-absurd-trillions so it should become clear now why you need robots, tons and tons of robots, to support at-scale experimental biology. Having robotic systems that can execute experimental protocols via API call isn’t a new idea. There have been many companies started proposing to do exactly this, notably Transcriptic back in 2012, and currently Gingko Bioworks (from which I stole the image above).
This is where the datacenter mental model starts to fall apart for biology in two respects: the first is in how the datacenter is constructed, the second is how the data is used and processed. For software applications the approach is stacking a large number of the same fundamental unit, a server, and providing sufficient infrastructure to operate them en-masse: fiber optical interconnect between servers, networking equipment to external internet, storage systems, power systems, cooling. There are different kinds of servers, some optimized for AI training and so contain GPUs, others more general purpose computing for web hosting, or storage servers that have dozens of hard drives, but they largely fit into standardized form factors and physical mounting configurations measured in U’s like 1U, 2U, 4U, 8U, etc, with some standardization of power and networking interfaces.
There are no such easy breaks in biology. The typical wet lab has dozens of different kinds of experimental equipment all with completely different interface methods that range from a couple hundred dollars, like an electrophoresis gel box, to a million dollars like an Illumina NovaSeq. Between these are centrifigues, deep freezers, incubators, PCR machines, varieties of microscope, plate readers, and robotic liquid handlers, fragment analyzers, and on and on. The core issue in automating experimental biology work is that each experimental design has a somewhat unique sequence of operations across different pieces of equipment, and in between are often bespoke sample preparation methods and handling. The initial exploratory work in nailing down a specific experimental protocol - as one might do on the biology PC - then translates into a larger at-scale experimental campaign, but the automation trade-off is ever present: the time it takes to setup the automation of the entire workflow through robotic systems and physical automation is often far more than just doing it manually, since once that particular experimental campaign is done the bespoke automation becomes moot.
This is why for the robotic data center of biology you absolutely need true general purpose robotics which implies fully autonomous vision-based guidance and navigation systems of humanoid-esque robots. Another way to frame this is experimental design in exploratory biological research is entirely dominated by the long-tail, and the cost and complexity of piecing together experimental equipment with fixed automation is a failing proposition as any specific configuration proves brittle to other use-cases.
The second big difference between the data center of software and that of biology is how the data is actually handled and managed: for software services data centers are part data routers, part data processors and generators, while for biology the more accurate label for a fully robotic wetlab able to carry out hundreds of thousands to millions of experiments at-scale is a data factory. What enters the factory are raw ingredients - reagents, cell lines, custom RNAs and sequences, and what comes out is massive volumes of data across a large number of modalities: mass spectrometry, single-cell RNA readouts, genome readouts, fluorescent microscopy data, transcriptomics data, on and on.
Where does it all go?
Not in the human mind, which can have great depth but narrow breadth - when looking at complex interactions across an entire organism, let alone a single cell, you start to need the intelligent mind of a computer.
Robots do the work, AI does the analysis, because humans aren’t smart enough to understand themselves anyway.
We don’t normally think of biological systems as an industrial production method, but when you compare them they seem miraculous. The standard industrial production method at a high level is to extract vast quantities of ‘mixed up stuff’ - like rocks and dirt that contain different metal ores, chemically separate and purify those ores into metals, recombine the metals into alloys, do a similar thing with hydrocarbons to produce plastics and polymers, and then with all our highly purified extracted goods recombine them into something like a hip implant, circuit board, computer, rocket ship, etc. We go from highly-mixed composite to highly-pure extract and back to highly-mixed composite and this is extremely energy intensive simply because from thermodynamic first principles you’re producing a lot of entropy via the separation and purification process, not to mention the actual efficiency of chemical reactors being not-so-great.
Biological systems work in a completely different manner with chemical reactions that can be 100 - 1000x more energy and resource efficient by enzyme catalysis. Think about a person and their digestive and circulatory system - do you eat a salad, all the components get cleanly separated into little piles of different amino acids in a storage facility, and then shipped out to where they are needed? No, not at all. Living systems ingest bulk material in aggregate and composite form, digest it all together, and then put the building blocks directly into circulation in the bloodstream where they are picked up and assembled in-situ into muscle tissue, bones, epithelial tissue, etc. From an end-user perspective it is far simpler: just pour the raw inputs all into the same hopper, and it’ll get churned up, and turn into the right stuff. To be so simple from a user perspective it is orders of magnitude more complicated from an implementation perspective, and that complexity of implementation is something that requires molecular nanobots to undertake.
We are just starting to program nanobots from scratch, in the form of synthetic biology, and its the robotic data factory of biology that can produce enough information to enable a super-intelligence of the near future to design a novel organism or ecosystem from scratch, re-purposing the nanobot infrastructure away from what it usually does - keep an animal alive and let it run around - into something we accomplish with industrial methods, like mass producing vehicles or building rockets.
Crack the Biological Tech Stack and Plant a Rocket
Let’s now imagine what it would be like if we fully decode the biological tech stack and can program nanobots to build things the way biological systems do - without any tedious refining, purification, and manual assembly.
You want a rocket ship. Great. You take a thumb-sized “rocket seed” and plant it in the middle of the desert. It starts by melting its way into the sand, breaking apart silicates into silicon and oxygen to form a proto-computing-circuit board capable of more complex operations, sucking in CO2 from the air and producing carbon-nanotube arms and limbs that then dig further into the ground to access deeper minerals and resources, growing and crawling around and tunneling to find everything it needs - iron, phosphorous, copper, aluminum, nitrogen, as they’re found in naturally occurring molecular compounds, sometimes re-using the compounds wholesale and sometimes breaking them apart into new ones. After a couple weeks the rocket-seed has become a spiderweb network of tangled limbs extending deep into the Earth’s surface, pumping molten minerals and salts up through its internal ceramic circulatory system, sucking up huge quantities of water vapor and CO2 from the atmosphere and cracking it into methane and purified oxygen slowly filling up cavernous fuel tanks.
The rocket seed doesn’t just grow a rocket, but grows more rocket seeds as well and stores these aboard the ship. As it slowly ripens the supporting structural scaffolding starts to whither way and becomes weaker and weaker, ready to crack and separate from the rocket as soon as its internal ignition sequence reaches its programmatic maturity phase. The rocket launches, the circulatory and skeletal system left behind begins the long process of growing another rocket.
Now that’s a science fiction future I can believe in.
inspiring and excitingly speculative.
Life occurs mostly in/around water. Would like to hear more about water (e.g. Gilbert Ling, interfacial water, Gerald Pollack's lab, et al.)
Life, as author notes, is not all human/human-understandable. From this perspective, would like the view from Michael Levins (Tufts) perspective.
First suggested application: Thing that clears out our microplastics, gifted from the last Great Tech Thing that saved us lots of time and money...
Great piece, Andrew. This is indeed a science fiction vision I can believe in.
You discuss the potential of emerging AI systems that can think or reason alongside the need for general-purpose robotics that can operate in the physical world we inhabit. I think this is coming soon, ~2030.
We are making progress on both fronts, largely independently of each other, two threads of advancement. Humanoid robots benefit from advances in battery technology, sensors, and electric motors, while our LLMs are quickly saturating every test we can devise for them.
As I've written, once these two threads of advancement merge, like the double helix of DNA, spiraling and reinforcing the other, everything changes. Our thinking machines that operate in the world of bits will, for the first time, touch the world of atoms. From there, a new world begins. One of unimaginable abundance and possibility.